

Core thesis
Most agents today are text-based. The LLM is the main working medium, forcing everything into prompts: memory, tool descriptions, context, results, policies, and state.
Executable graph agents shift the medium. They operate on a graph of typed objects, relationships, actions, functions, and code. The model still reasons, but the system doesn't have to carry its entire state as text.
Buffaly implements this idea using ProtoScript.
1. Introduction: text-based agents vs. executable graph agents
The standard agent loop looks like this:
- User text
- → LLM
- → Tool call
- → Text / JSON result
- → LLM
- → More tool calls
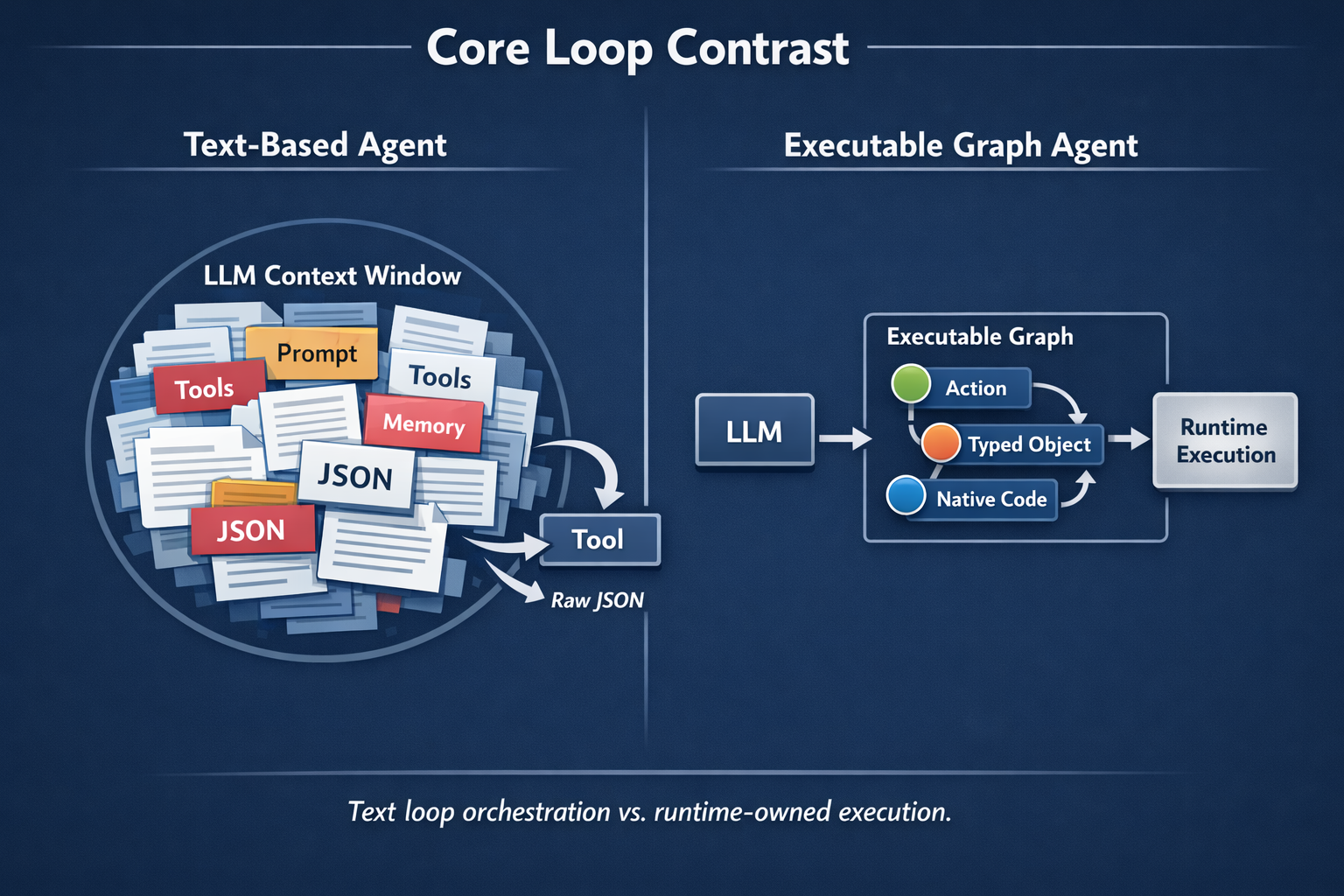
The model constantly reads, interprets, and reacts to text.
An executable graph agent works differently. It does not only store knowledge as text or retrieve similar examples. It stores objects, relationships, and actions in a structure the system can execute.
An executable graph is a graph where the things the agent knows can also become things the agent can act through.
A node is not just a fact. It can be a typed object. A typed object can be passed into a function. A function can become an action. An action can become a reusable tool.
Buffaly is my implementation of this idea. It uses ProtoScript as the working medium for typed objects, relationships, functions, actions, native objects, and runtime learning.
What is an executable graph?
An executable graph is neither a graph database with attached functions, nor a programming language with metadata.
It is a runtime substrate. Entities, objects, functions, and actions live in one addressable structure. Nodes and edges aren't just queried facts—they are values and capabilities the runtime executes, mutates, and extends.
The graph isn't just representational. It's operational.
Consider a node like:
CareProgram#APCMis not just a label meaning “Advanced Primary Care Management.” It can be:
- a semantic entity discoverable from language like “APCM”
- a typed object, such as
NonTimeBasedCareProgram - a holder of structured fields like billing codes and requirements
- a value passed into a function
- a dispatch participant that changes which logic applies
- a provenance anchor
- a thing the system can later deepen, relate, or use in new actions
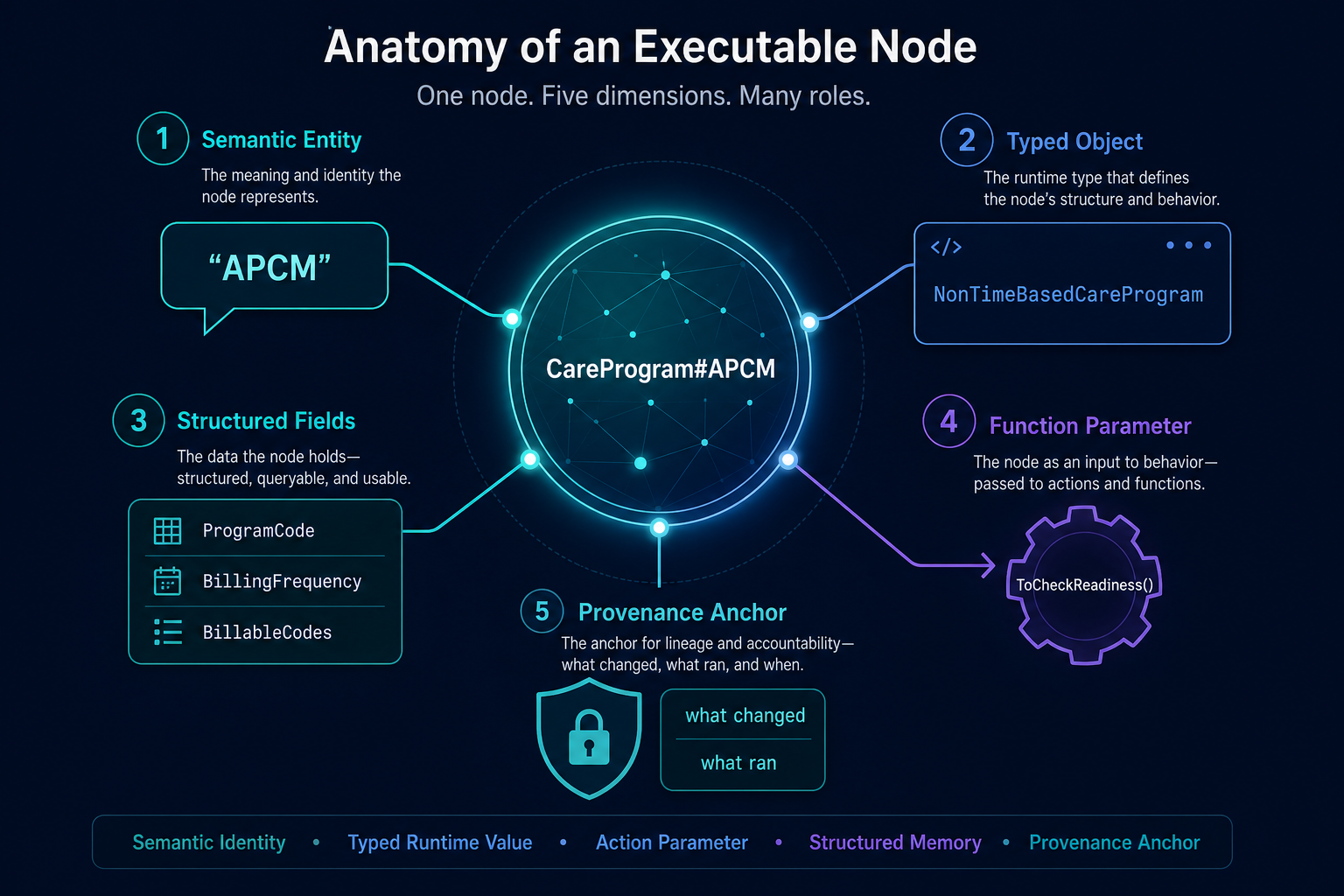
The graph is executable because its elements participate directly in runtime behavior. They are not just retrieved into context for the model to reinterpret.
For example:
ToCheckReadiness.Execute(Patient#A17F, CareProgram#APCM)In a text-agent architecture, APCM would usually be prompt text, retrieved documentation, JSON, or a graph fact. The model must re-read and apply it.
In an executable graph architecture, CareProgram#APCM is resolved by the runtime as a typed object. Its type and fields affect which functions are valid, which checks run, and what actions are available next.
That is the key distinction: the ontology tells you what APCM means; the executable graph makes that meaning runnable.
An ontology primarily defines meaning. It gives you classes, instances, properties, relationships, constraints, and sometimes inference rules. An ontology can say that APCM is a care program, that it is non-time-based, and that it has billing codes G0556, G0557, and G0558. That is useful, but it does not necessarily define the operational path for what should run against a patient, a payer, a billing month, and a care program.
An executable graph includes ontology-like structure, but adds runtime semantics. It can resolve the phrase “APCM” to CareProgram#APCM, pass that typed object into an action, keep native objects inside the runtime, expose only controlled handles or summaries to the model, and record the provenance of what happened.
So an ontology makes meaning machine-readable. An executable graph makes meaning runnable.
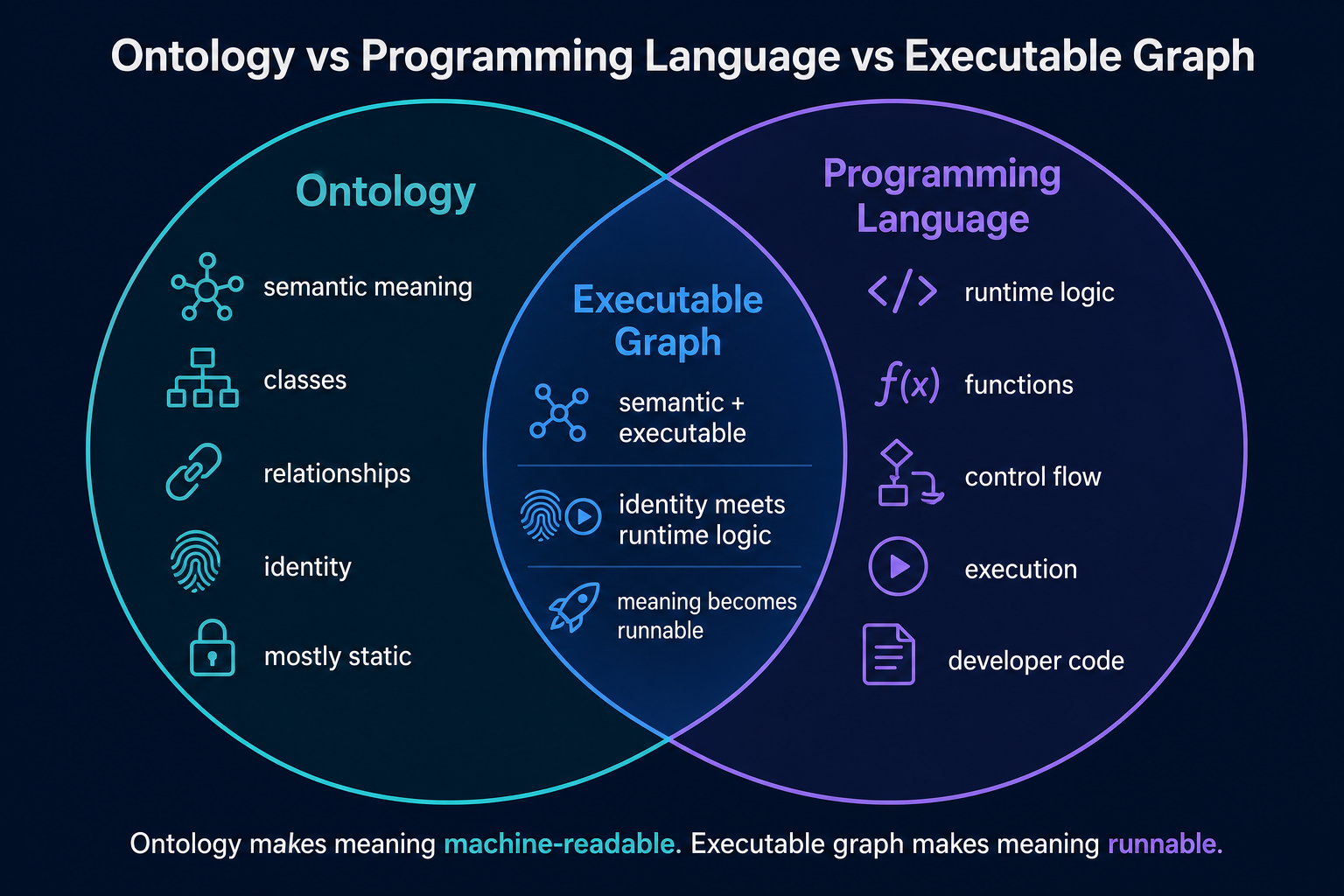
A programming language like JavaScript is different in the opposite direction. JavaScript is executable, but it is not inherently a semantic agent substrate. You can model APCM in JavaScript and write functions that operate on it, but JavaScript does not natively give you semantic entity annotations, language-grounded object identity, model-facing action discovery, typed agent-callable actions, provenance through a semantic/action graph, or runtime promotion from remembered fact to object to relationship to rule to action.
You can build those things in JavaScript, but JavaScript itself is not that system.
A programming language is primarily a medium for developers to express computation. An executable graph is a medium for an agent/runtime to organize knowledge and computation together so that language-resolved entities become typed runtime values, and typed runtime values can flow into executable actions.
The difference is not syntax. The difference is what the symbols are connected to.
CareProgram#APCM is simultaneously a semantic entity, a graph node, a typed object, a memory object, a runtime value, an action parameter, a provenance anchor, a discoverable target from natural language, and a participant in future graph mutation.
In JavaScript, apcm is just a variable unless you build a whole semantic/runtime system around it.
A concise way to put it is this:
- An ontology is semantic but not inherently executable.
- A programming language is executable but not inherently semantic.
- An executable graph is semantic and executable, with runtime identity connecting the two.
Or more directly: an executable graph is what you get when the knowledge graph, tool registry, type system, runtime object store, action dispatcher, and agent memory stop being separate systems glued together by prompt text and become one substrate.
2. Immediate example: online incremental learning by creating a new tool
Take a simple task: check APCM readiness for 15,000 patients.
If a text-based agent only has a single-patient tool, it's stuck. It either calls the tool 15,000 times, chunks the work awkwardly, or waits for a developer to build a batch tool.
Buffaly can do something else.
Because Buffaly’s tools are part of an executable graph, it can create a new batch action at runtime:
[SemanticProgram.InfinitivePhrase("to check APCM readiness for a batch of patients")]
prototype ToBatchCheckAPCMReadiness : MedicalAdminAction
{
function Execute(Collection Patients, CareProgram Program) : BatchReadinessResult
{
BatchReadinessResult Result = new BatchReadinessResult();
foreach (Patient Patient in Patients)
{
APCMReadinessResult SingleResult =
APCMReadinessChecker.Check(Patient, Program);
Result.Add(Patient, SingleResult);
}
return Result;
}
}Instead of 15,000 tool calls, the system executes one action.
A normal agent remembers that batching is better. Buffaly makes batching exist.
This highlights the core difference between remembering advice and creating executable capability:
- Code generation is cheap. Generating a script isn't the breakthrough.
- Runtime capability is valuable. Buffaly turns repeated successful reasoning into new runtime capability: it creates the action, loads it into the executable graph, exposes it as a callable tool, and uses it immediately.
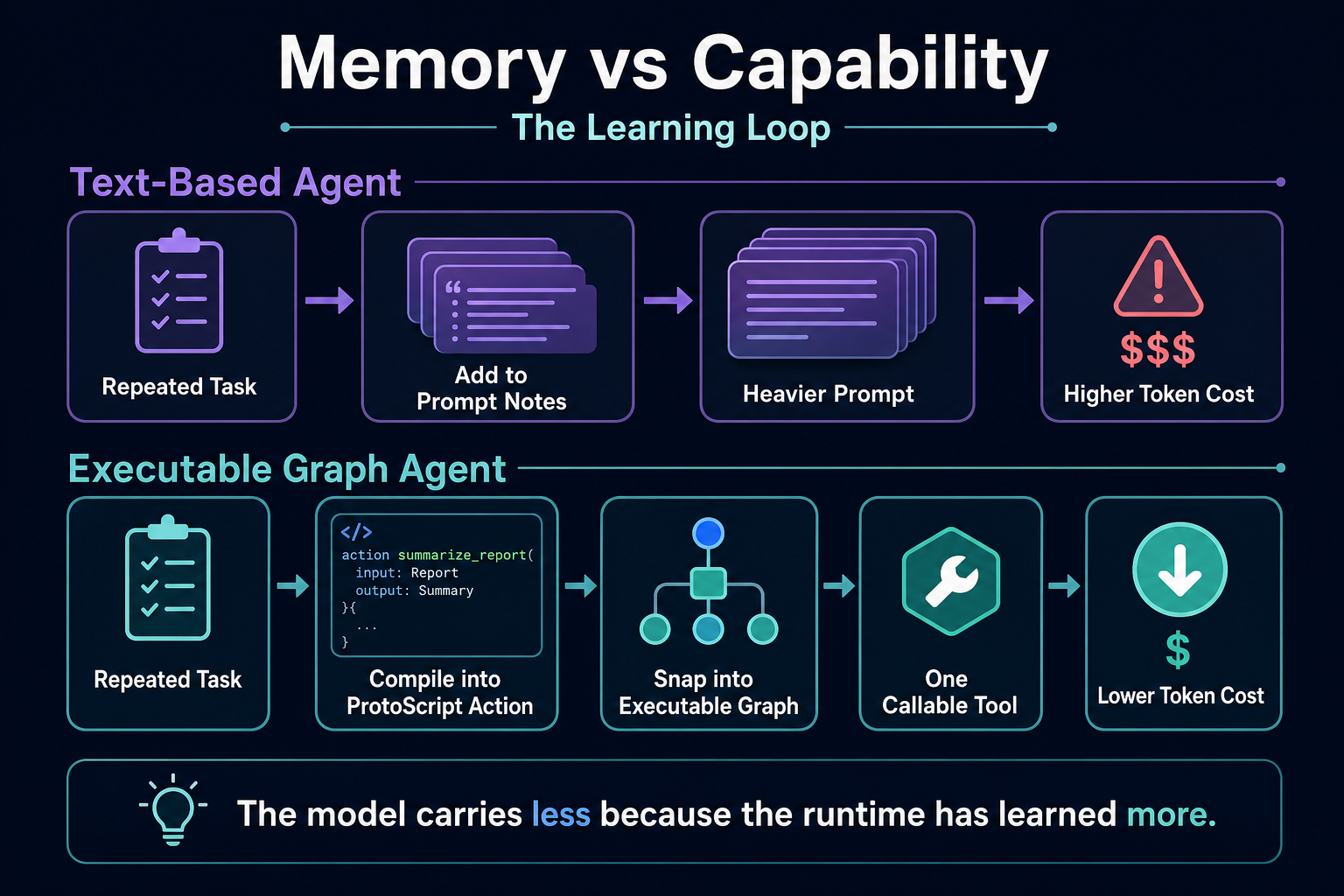
That changes the compounding curve. A text-based agent usually gets better by adding more context. An executable graph agent gets better by reducing what has to remain in context.
Repeated reasoning becomes a tool. Repeated tools become native execution. The model stops orchestrating loops that software can run directly.
This is where the cost argument comes from. In a text loop, more work usually means more tokens. The model keeps re-reading serialized data, tool outputs, policies, and intermediate state. In an executable graph, repeated work can move out of the prompt and into structured code. The system can become more capable while using fewer tokens for the same class of task.
That is the difference between accumulating memory and accumulating capability.
3. Where text-based agents start to strain
Text-based agents are useful, but their architecture has predictable limits. Because they turn everything into prompt material:
- tool descriptions
- tool results
- memory
- retrieved examples
- documents
- JSON payloads
- policies
- intermediate state
That creates several compounding problems:
- Tool selection gets noisy: The model must choose from increasingly large tool lists.
- Data gets flattened: Files, rows, records, tables, and objects degrade into plain text or JSON.
- Prompt injection becomes central: Untrusted text shares the same medium as core instructions.
- Cost scales poorly: More memory means more retrieval. More tools mean longer prompts.
- Learning is weak: The system can store notes, but it lacks a native way to turn repeated work into executable capability.
4. What an executable graph changes
An executable graph changes the medium the agent works in.
Instead of:
- Text memory + tool descriptions + JSON outputs
the system has:
- Typed objects + relationships + functions + actions + runtime state
This matters because the agent can act through the graph.
A concept can become a typed object:
partial prototype CareProgram#APCM : NonTimeBasedCareProgram
{
ProgramCode = "APCM";
BillingFrequency = "Monthly";
}That object can be passed into a function:
ToCheckReadiness.Execute(Patient#JohnDoe, CareProgram#APCM, BillingMonth#February);The fact that APCM is non-time-based is not just a sentence in a prompt. It becomes part of the runtime behavior. The type of the object can change which code path runs.
A standard graph database can store facts. But an executable graph isn't just storage. It promotes facts into typed runtime values that actively dictate execution.
5. Buffaly’s implementation: ProtoScript
ProtoScript is Buffaly’s working language. It is a practical language built for agents, not a pure academic ontology language.
It combines:
- prototype-based objects
- semantic entity annotations
- typed functions
- executable actions
- runtime mutation
- native object handling
- C# interop
ProtoScript gives Buffaly a place to put learning that is more useful than another paragraph of instructions.
- A repeated fact can become an object.
- A repeated procedure can become an action.
- A repeated action can become native code.
- A native object can move through the runtime without becoming prompt text.
LLMs are good at reading and writing code. Buffaly uses that strength. The model can help write ProtoScript, but the runtime can execute and validate it.
6. Typed tools, native objects, and controlled model exposure
In a normal agent, a tool usually receives strings or JSON.
In Buffaly, an action can receive typed parameters:
function Execute(Decimal Minutes, RemoteCareProgram Program) : StringOr native C# objects:
function Execute(String MRN) : Patient
{
return PatientLookup.FindPatientByMRN(MRN);
}The Patient object does not need to be serialized into the model context. Buffaly can hold it in memory and pass it into the next action.
Normal agent:
- MCP returns patient JSON
- → JSON goes into LLM context
- → model reads patient data
- → model calls next tool
Buffaly:
- C# returns
Patientobject - → Runtime holds
Patientobject - → Next action receives
Patientobject - → Model sees a handle or controlled summary
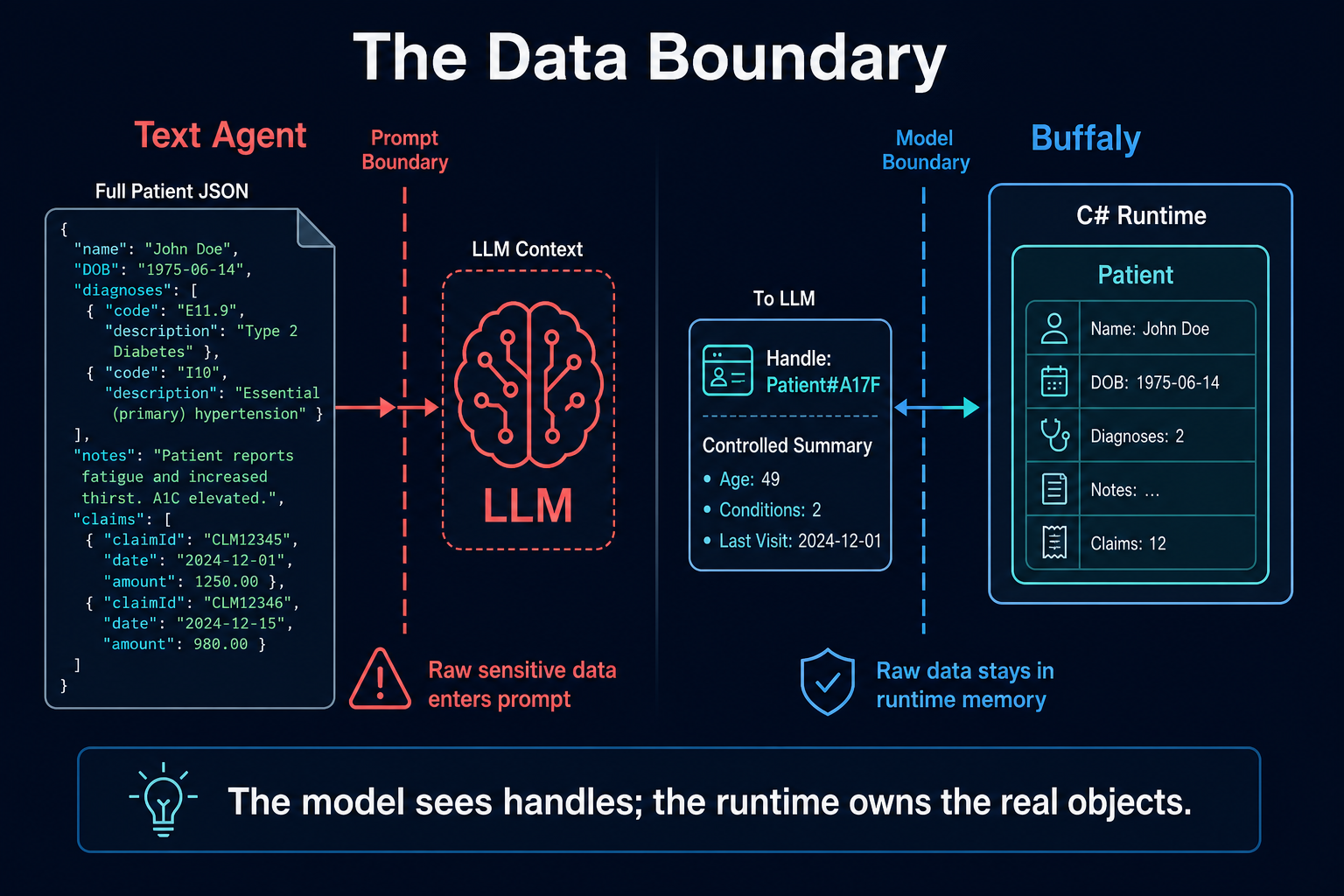
This is not just smarter prompting. It changes the data boundary.
7. Why this matters: agents that can rewrite their own working surface
Every agent framework can call tools. Buffaly changes its tool surface while working.
When the system repeatedly reasons through a pattern, that pattern doesn't remain a prompt note. It becomes a typed object, a rule, an action, then native code. Repeated reasoning compiles into runtime capability.
Text-based agents get better by carrying more text: more memories, examples, and summaries. Buffaly gets better by moving knowledge out of the prompt and into the executable graph.
That changes both capability and cost.
In a text loop, more capability usually means more tokens. The model has to keep rereading the same policies, examples, JSON payloads, tool outputs, and intermediate state. Every repeated workflow competes for context space.
In Buffaly, repeated work can be compiled into structured code. The model does not have to orchestrate a loop that the runtime can execute directly. It does not have to read 15,000 patient summaries if the runtime can hold native patient objects and run a typed batch action. It does not have to remember every rule in prompt text if the rule has become part of the executable structure.
That is the real compounding curve: the system learns more, but the model has to carry less.
This naturally improves safety beyond prompt hardening. Sensitive data stays behind runtime handles. Actions are constrained by typed objects. Auditability relies on actual code paths and provenance records, not just a model's transcript of what it claimed to do.
So the point is not simply that executable graph agents are more efficient. The point is that they can accumulate capability as software. They can continuously push useful text into structured code. They can acquire knowledge, make that knowledge operational, and then use the improved runtime surface on the next task.
That is what makes the architecture personal in a deeper sense: the agent can grow from actual work, learn recurring patterns, and turn those patterns into durable capability instead of endless context.
8. Conclusion: the foundation
This article introduces a new architectural category rather than an exhaustive feature list.
Text-based agents are the dominant pattern today. They are useful, but they are limited by the fact that the model has to keep operating over text.
Executable graph agents are a different direction. They give the model a structured environment to work inside: typed objects, actions, functions, native data, code, provenance, and a learning loop.
Buffaly is still early, and this article only covers the foundation.
Once you start building agents around executable graphs instead of text, a lot of things change: learning, tool creation, object handling, cost, control, and auditability.
I will be writing more about ProtoScript, runtime learning, native objects, and the internals behind Buffaly.
Buffaly points toward Ultra-Personal Agents: systems that genuinely grow and learn. Once you experience the difference between merely remembering instructions and actively compiling them into executable capability, it’s hard to go back.