Secure, deterministic semantic data access with grounded outputs
SemDB is a semantic database developed by Intelligence Factory to
address the limitations of existing retrieval and generation
systems when working with legacy, fragmented, or semantically
complex data. Built as part of our core technology stack in
Orlando, Florida, SemDB is designed for environments where trust,
auditability, and system integration are essential—especially in
regulated industries like healthcare. Unlike vector-only or
generative systems that suffer from hallucinations, semantic
ambiguity, and limited reasoning capability, SemDB uses structured
ontologies, hybrid embeddings, and local integration to create a
data layer that can be queried deterministically and acted upon
directly.
The Problem
Why Existing Systems Fail - Comparison
Capability
Typical RAG Systems
SemDB
Complex Query Handling
Often returns plausible but incorrect results due to
weak semantic grounding
Returns precise, ontology-aligned results for
domain-specific queries
Relational Understanding
Lacks structure; can't model policy rules or
cross-record relationships
Understands formal relationships via graph and
ontology logic
Execution Capability
Stops at retrieval; no ability to trigger actions or
update data
Can populate fields, tag records, or trigger
downstream routines
Security & Compliance
Cloud-based with potential for data leakage and
compliance risk
Runs locally, encrypts data, and supports controlled connectivity policies
Off-the-shelf retrieval and RAG (Retrieval-Augmented Generation)
systems have several limitations that made them unsuitable for our
use cases:
Inaccuracy in complex domains: Traditional RAG
architectures depend on word embeddings to retrieve similar
chunks of text. This leads to semantically plausible but
incorrect results when queries are nuanced or
domain-specific.
Lack of relational understanding: Vector
databases retrieve data based on similarity, not structure. They
can't represent relationships like "which billing
codes apply under insurer X's policy" or "which
records are incomplete across systems."
No execution layer: RAG systems stop at
retrieval and augmented text generation. They cannot update a
database, fill in missing fields, or act on the retrieved
information.
Cloud dependency and security concerns: Many
vendor solutions require data to leave the local environment,
creating compliance risk and complicating integration with
secure legacy systems.
We built SemDB in-house to resolve these constraints and support
our need for structured, secure, ontology-aware data access that
integrates seamlessly into existing systems.
Design and Implementation
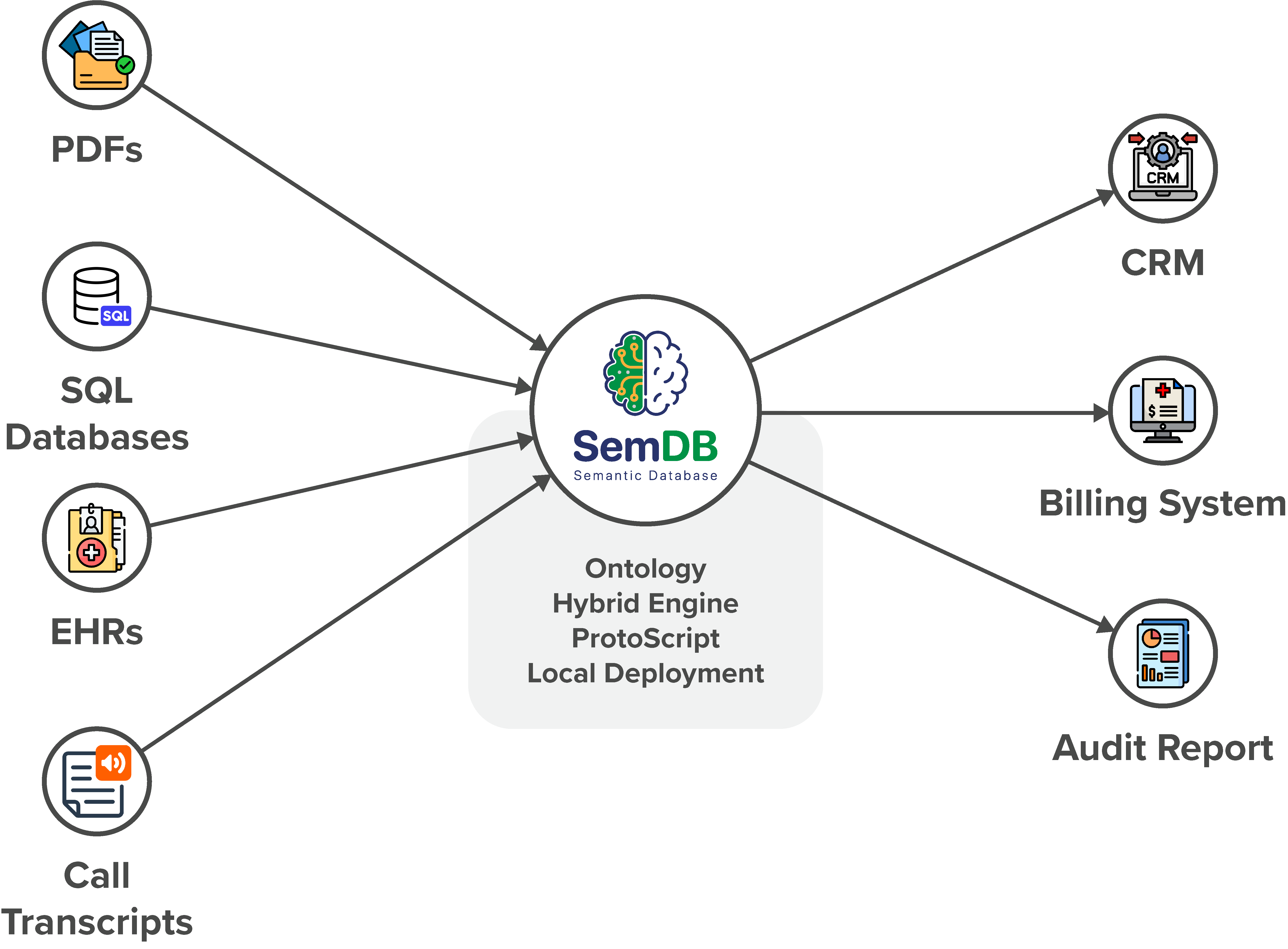
SemDB is deployed as a local semantic data layer that unifies
structured and unstructured data sources—from PDFs and call
transcripts to SQL databases and EHRs. It uses the following
architectural elements:
Buffaly Grounding and Policy Validation Layer
Buffaly grounding and policy validation layer:
A structured ontology defines domain-specific concepts,
properties, and relationships. Buffaly interprets queries with
contextual awareness, enabling precise filtering and
disambiguation with policy-verified outputs and auditable traces.
Relevant, Structured Results
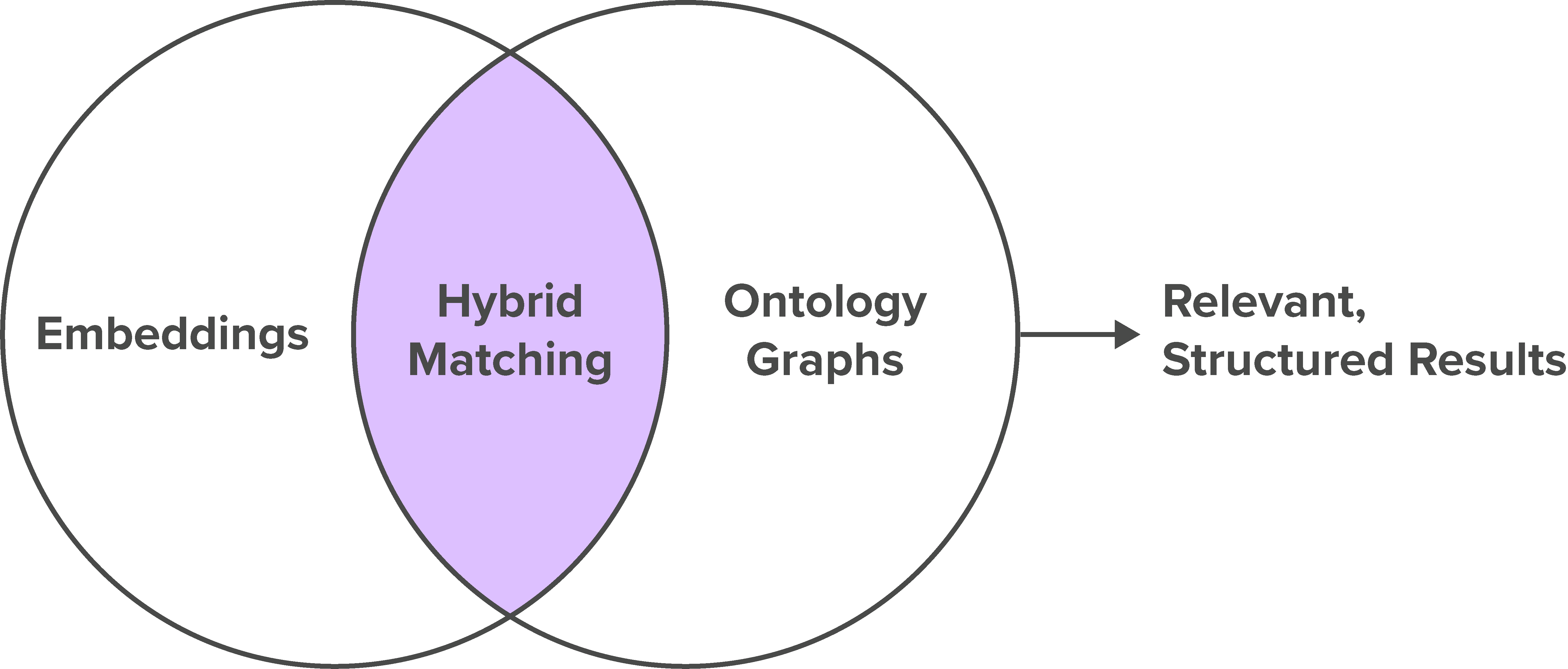
Hybrid Retrieval Engine: Combines vector
embeddings for similarity scoring with symbolic graph traversal
and ontology alignment. This allows SemDB to match intent with
both contextual meaning and formal structure.
Deterministic, rules-based logic
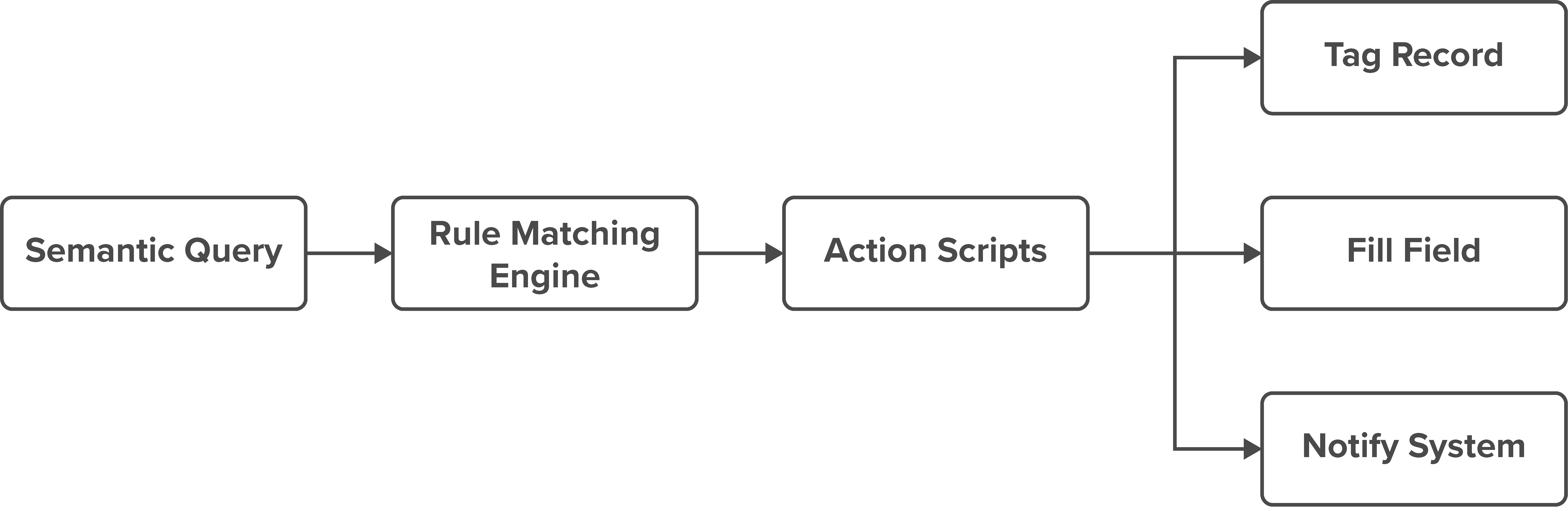
ProtoScript Execution Layer: Semantic queries
can trigger action routines via ProtoScript, a rule-based
scripting language developed internally. This allows SemDB to
populate missing fields, tag records for review, or integrate
directly with CRM, billing, or workflow systems.
Semantic Extraction Pipeline: For unstructured
data, such as audio transcripts or documents, SemDB extracts
entities and relations and stores them as structured JSON
aligned with the ontology. These can be used immediately to
update other systems.
Deployment Model: SemDB is designed to run
locally or in private infrastructure, with no data egress. It
integrates via standard REST APIs and supports formats like
JSON-LD for structured export.
Example Applications
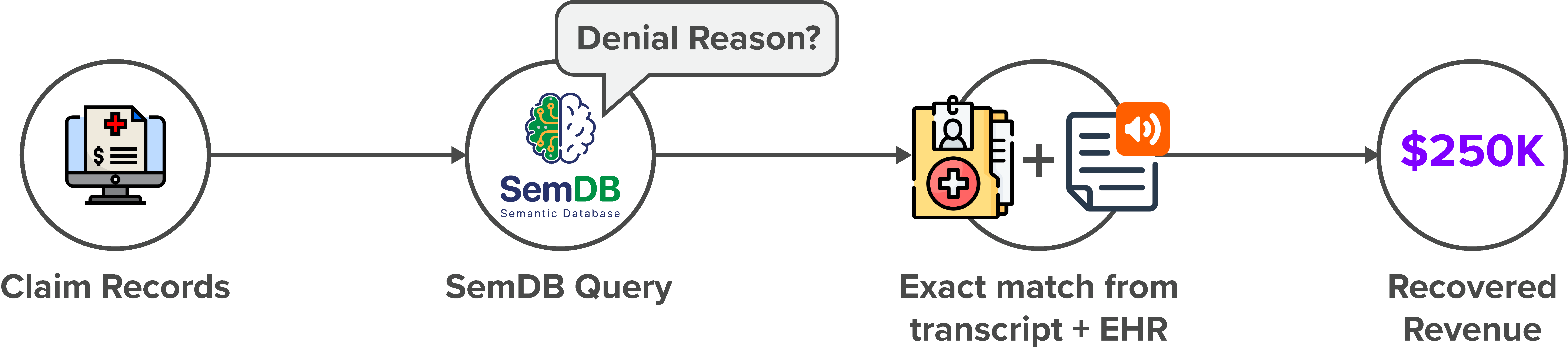
Healthcare Claims Workflows: At Medek Health
Systems, SemDB enables retrieval of insurer-specific policies,
billing codes, and denial reasons from legacy EHRs and call
transcripts. It has supported the processing of ~1 million
claims with a 90% success rate and recovered over $250K in
otherwise unrecoverable cash flow.
CRM Data Hygiene: SemDB extracts contact
information from unstructured call transcripts and automatically
updates missing fields in CRM records, improving data quality
and reducing manual entry by over 70% in some deployments.
Supply Chain Audits: In manufacturing contexts,
SemDB maps shipment delays, supplier performance, and inventory
status across multiple internal databases. The semantic layer
allows direct querying of state transitions and relational
events over time.
Key Characteristics
Deterministic, Grounded Outputs: Responses are
retrieved from validated data and constrained by ontology-backed
policy logic, reducing ambiguity and improving auditability.
Structured and Unstructured Data Fusion:
Supports both schema-first ingestion (from SQL and spreadsheets)
and unstructured extraction (from PDFs, emails, and
transcripts), harmonized through the ontology.
Real-Time Actionability: Extracted data can be
transformed and dispatched immediately, enabling automation of
downstream systems.
Scalability: In-memory graphs for development;
persistent ontology-backed storage for production. Proven scale
to tens of thousands of documents with sub-second retrieval.
Security and Compliance: Runs locally, encrypts
data with AES-256, and meets HIPAA/GDPR requirements. Supports
deployments with no data egress on sensitive paths and governed
model integrations when needed.
Why We Built It
We needed a system that could:
Understand structured and unstructured legacy data
Retrieve precise answers under formal constraints
Act on that data deterministically
Remain fully auditable and secure
No existing tool provided this combination. SemDB is the result of
that gap—a semantic system built for controlled environments,
real-world data messiness, and execution-focused use cases.
Learn More
SemDB is now a core layer in our technology stack, enabling safe
and explainable AI across medical billing, CRM automation, and
internal data harmonization. For technical documentation or a
demonstration, visit semdb.ai.