





In
Volodymyr Pavlyshyn's article
, the concepts of
Metagraphs and Hypergraphs
are explored as a transformative framework for developing relational models in AI agents’ memory systems. The article highlights how these metagraphs can act as a semantic backbone, enabling AI to retain context, process relationships, and make informed decisions more effectively. It also dives into the intricacies of implementing metagraphs and their associated challenges, illustrating the potential of these structures to revolutionize AI memory systems.
At Intelligence Factory, we’ve taken concepts like Metagraphs and Hypergraphs and made them
accessible and easy to implement
through our cutting-edge graph technology. Our ontology-driven framework simplifies what might otherwise be a technically demanding process, empowering developers to create scalable, context-aware AI systems with ease. In this article, we’ll show how Buffaly’s advanced graph technology can create and deploy Metagraphs and Hypergraphs, unlocking their full potential without the complexities traditionally associated with their implementation.
This article delves into the concepts of
metagraphs
and
hypergraphs
, their significance in knowledge representation, and how Buffaly leverages these structures with ProtoScript to push the boundaries of AI development.
What is Chunking, and Why is it Necessary?
Chunking is the process of dividing large bodies of text into smaller, semantically coherent units. Effective chunking ensures that these segments are meaningful enough to provide context but concise enough to fit within the LLM's context window.
For instance, traditional methods like character-based chunking or recursive splitting by separators often fail to preserve semantic meaning, leading to fragmented information. Semantic chunking, by contrast, leverages advanced transformer models to create embeddings of text, identifying natural breakpoints based on conceptual differences. This approach improves information retrieval, enabling tasks like summarization, contextual retrieval, and structured understanding of extensive texts.
What is a Hypergraph?
A hypergraph generalizes traditional graphs by allowing edges (hyperedges) to connect any number of nodes, not just two. This makes hypergraphs ideal for representing multi-entity relationships, such as collaborative projects or interrelated datasets.
Example:
A hyperedge in a hypergraph might represent a project team, linking all team members as a single entity.
What is a Metagraph?
A metagraph is an advanced type of graph structure that incorporates meta-relationships—higher-order connections that go beyond simple pairwise relationships between nodes. These are particularly valuable in systems where understanding context and complex dependencies is crucial, such as knowledge representation and reasoning.
Example:
In a metagraph, a relationship can itself be a graph, enabling nested or hierarchical structures that mirror real-world complexities.
Hypergraphs, Metagraphs, and Why They Matter
Let’s face it— hypergraphs and metagraphs sound like something out of a graduate-level math class. They’re esoteric concepts that most of us don’t encounter day-to-day. But here’s the thing: they actually help us understand an important limitation of traditional knowledge graphs.
1. Traditional Graphs Are Stuck in Triples
Knowledge graphs are built around triples—basic "subject-predicate-object" relationships, like "John likes pizza" or "Earth orbits the Sun." While this format works for simple data, it struggles with complexity. The power of any language lies in its ability to express ideas , and triples are like speaking in three-word sentences. They can’t capture the richness of relationships we naturally understand, like "John likes pizza when it’s from New York but only on Fridays."Hypergraphs and metagraphs show us that there’s more to the story. They allow relationships to connect more than just two entities or even describe relationships between other relationships, breaking free from the triple trap.
2. Graphs Should Mirror How We Think
Building graphs that mirror human thought should be simple. We don’t think in rigid, disconnected triples—we think in webs of context, nuance, and relationships. For instance, if you’re planning a vacation, your mental "graph" might link flights, weather forecasts, hotel ratings, and costs, all dynamically influencing one another. Traditional knowledge graphs struggle with this level of complexity, but concepts like hypergraphs and metagraphs remind us that it shouldn’t be this hard.The point is: our tools for representing knowledge should be as flexible as our thinking. Hypergraphs and metagraphs might seem abstract, but they push us to rethink what’s possible and build systems that can truly reflect the complexity of the world around us. Implementing Complex Graphs with Buffaly and ProtoScript In Buffaly, hypergraphs and metagraphs can be effectively modeled using ProtoScript, an ontology-focused language designed to simplify the creation and management of these complex structures. The point isn’t to create complex structures, it’s to make complex ideas easy to represent. Below is a simple example of how we can model relationships ProtoScript. We use ProtoScript to define our Ontology:
// Define basic graph structure
prototype TeamMember
{
Team Team;
}
prototype Team
{
Collection<TeamMember> TeamMembers;
}
// Add edges and connections
prototype IntelligenceFactoryTeamMember : TeamMember
{
Team.Team = IntelligenceFactoryTeam;
}
prototype Matt : IntelligenceFactoryTeamMember;
prototype Justin : IntelligenceFactoryTeamMember;
prototype Giancarlo : IntelligenceFactoryTeamMember;
prototype Flavio : IntelligenceFactoryTeamMember;
prototype IntelligenceFactoryTeam
{
Team.TeamMembers = [Matt, Justin, Giancarlo, Flavio];
}
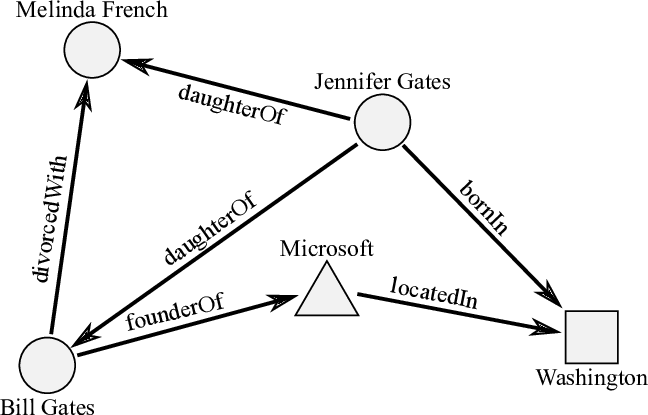
This is a fairly simple graph, and very familiar to programmers. It establishes the following relationships:
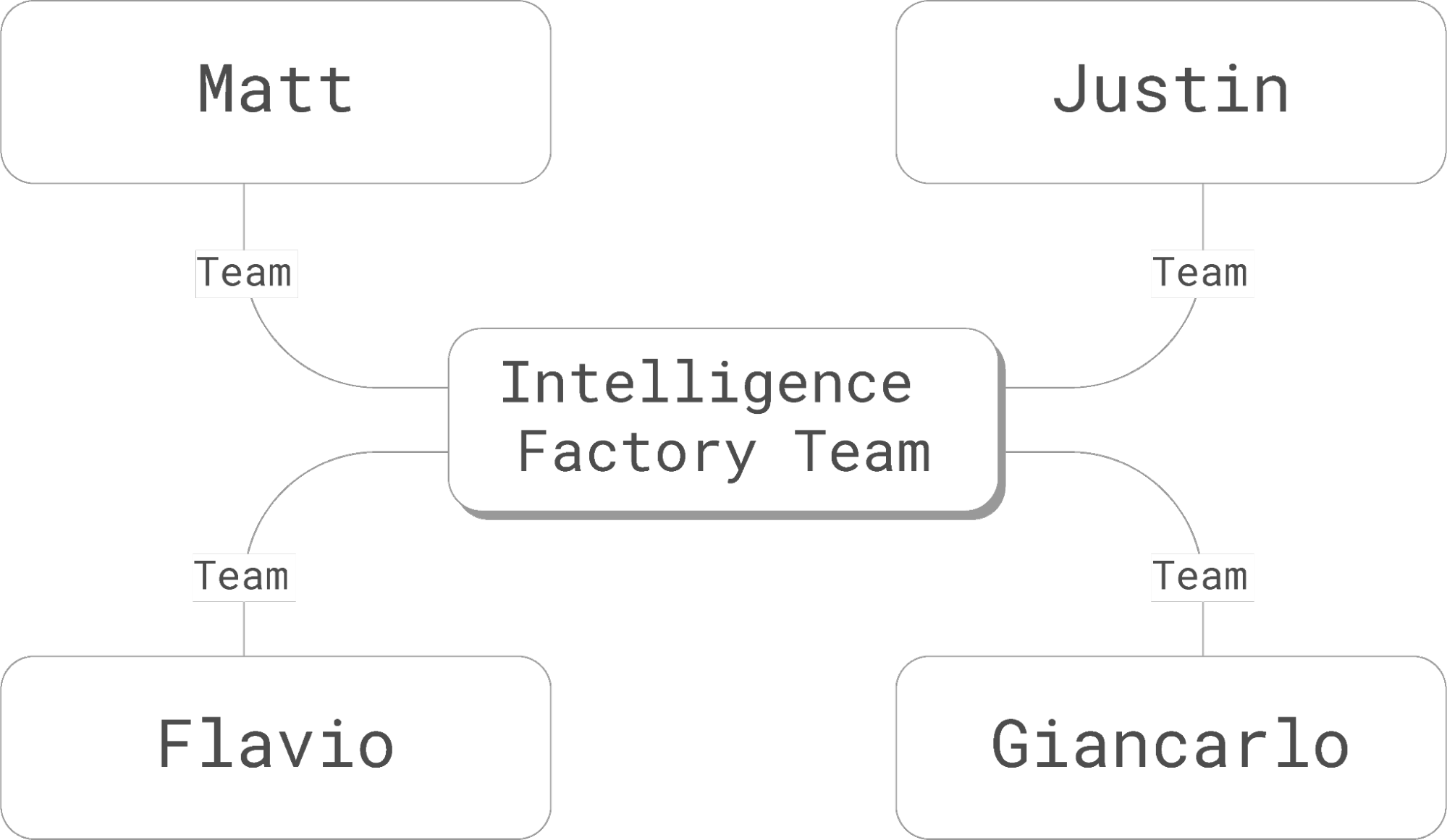
For comparison, here is a similar graph implemented in RDF format:
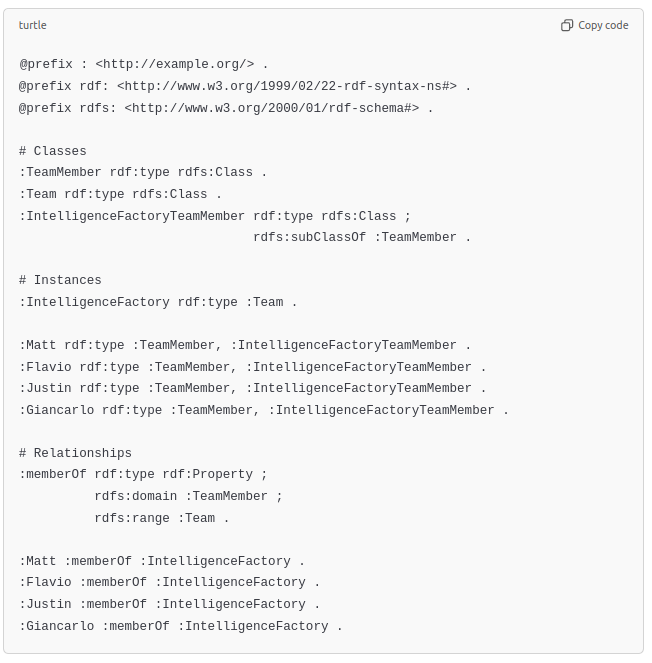
In short, ProtoScript lets us define an Ontology that is easy to understand and easy to use.
Graphs with Temporal (Time) or Other SubTypes
Metagraphs allow relationships themselves to be structured as graphs, enabling nuanced and hierarchical representations. This is particularly useful in modeling temporal or contextual relationships.In ProtoScript, we can quickly set up graphs that represent temporal or other relationships that mirror the way we think.
// Define entities and attributes
prototype UnitedStates : Country;
prototype Brazil : Country;
prototype Germany : Country;
prototype Tense;
prototype Future : Tense;
prototype Past : Tense;
prototype Present : Tense;
// Define relationship structure
prototype President
{
Country Country;
Tense TimeFrame;
}
// Subtypes for Metagraph relationships
[SubType]
prototype PresidentOfUnitedStates : PresidentOf
{
function
IsCategorized
(
) :
bool
{
return
this
-> {
this
.Country
typeof
UnitedStates };
}
}
[SubType]
prototype FormerPresident : President
{
function
IsCategorized
(
) :
bool
{
return
this
-> {
this
.TimeFrame
typeof
Past };
}
}
// Use relationships in the metagraph
JoeBiden
typeof
President;
// true
JoeBiden
typeof
PresidentOfUnitedStates;
// true
AngelaMerkel
typeof
PresidentOfUnitedStates;
// false
DonaldTrump
typeof
PresidentOfUnitedStates;
// true
DonaldTrump
typeof
FuturePresident;
// true
DonaldTrump
typeof
FormerPresident;
// true
This example introduces an important concept: dynamic subtypes. It allows us to divide our categorizations into important subtypes, useful for easier operation.
- Subtypes are automatic
- Subtypes are dynamic, they will change with the underlying data.
- Subtypes allow a combinatorial number of categorizations
The other concept we added in this example was the idea of functions within our Ontology. Remember, ProtoScript is a programming language – it’s not a data specification language (like RDF). It is self mutable.The above graph cannot be expressed the same way in RDF format (or any common Graph format) as it is declarative.
Having the ability to nest functions within the graph gives us a lot of power. Look back at these previous statements and add functions that automatically build the ontology for us.
// Define basic graph structure
prototype TeamMember
{
Team Team;
//Constructor
function
TeamMember
(
) :
void
{
this
.Team.Add(
this
);
//automatically build the Team.TeamMembers collection
}
}
prototype Team
{
Collection<TeamMember> TeamMembers;
}
prototype IntelligenceFactoryTeam;
prototype TeamAmericaTeam;
prototype TeamBrazilTeam;
prototype IntelligenceFactoryTeamMember : TeamMember
{
Team.Team = IntelligenceFactoryTeam;
}
prototype Matt : IntelligenceFactoryTeamMember;
prototype Justin : IntelligenceFactoryTeamMember;
prototype Giancarlo : IntelligenceFactoryTeamMember;
prototype Flavio : IntelligenceFactoryTeamMember;
This shortcut helps us to maintain the Team.TeamMembers collection without any extra work.
Why is this important?
The Ontology is meant to store data in a way that mirrors the way we 1) think about ideas and 2) retrieve information. Compare a simple query:
Who are the members of Intelligence Factory Team?
In ProtoScript
IntelligenceFactoryTeam.TeamMembers [Matt, Justin, Giancarlo, Flavio]
In SPARQL (for Knowledge Graphs)

The difference:
- The ProtoScript version is a quick lookup, there is no scan. The information is already organized
- The SPARQL needs to scan the nodes, looking for one(s) that satisfy the constraint.
The difference:
Multi-hop graph navigation are easy also:
Who is on Matt’s Team?
Matt.Team.TeamMembers
[Matt, Justin, Giancarlo, Flavio]
Conclusion
While you may be consciously using Metagraphs and Hypergraphs to solve problems, it is nice to have the flexibility of a powerful graph based programming language like ProtoScript. By enabling these advanced structures, Buffaly unlocks capabilities far beyond traditional graph-based systems, allowing for:
- Better Contextual Understanding: Representing nested and hierarchical relationships.
- Enhanced Decision-Making: Leveraging semantic memory for more informed outcomes.
- Scalability and Flexibility: Handling complex, non-pairwise relationships with ease.
We’ve only scratched the surface of what can be done with Ontologies built on ProtoScript. What’s most important, however, is that you can take advantage of these technologies with our consumer focused products: FeedingFrenzy.ai and SemDB.ai . Both are built on this infrastructure and offer features that make running your business easier. For the more technical side of things, feel free to check out Buffa.ly .