


In the ever-evolving landscape of AI and natural language processing, Retrieval-Augmented Generation (RAG) has emerged as a cornerstone technology. RAG systems allow large language models (LLMs) to access vast knowledge bases by retrieving relevant snippets of information, or "chunks," to generate coherent and accurate responses. However, creating these chunks is not a trivial task. One of the most critical challenges in RAG is the chunking strategy itself—how we break down complex documents into meaningful, retrievable pieces.
What is Chunking, and Why is it Necessary?
Chunking is the process of dividing large bodies of text into smaller, semantically coherent units. Effective chunking ensures that these segments are meaningful enough to provide context but concise enough to fit within the LLM's context window.For instance, traditional methods like character-based chunking or recursive splitting by separators often fail to preserve semantic meaning, leading to fragmented information. Semantic chunking, by contrast, leverages advanced transformer models to create embeddings of text, identifying natural breakpoints based on conceptual differences. This approach improves information retrieval, enabling tasks like summarization, contextual retrieval, and structured understanding of extensive texts.
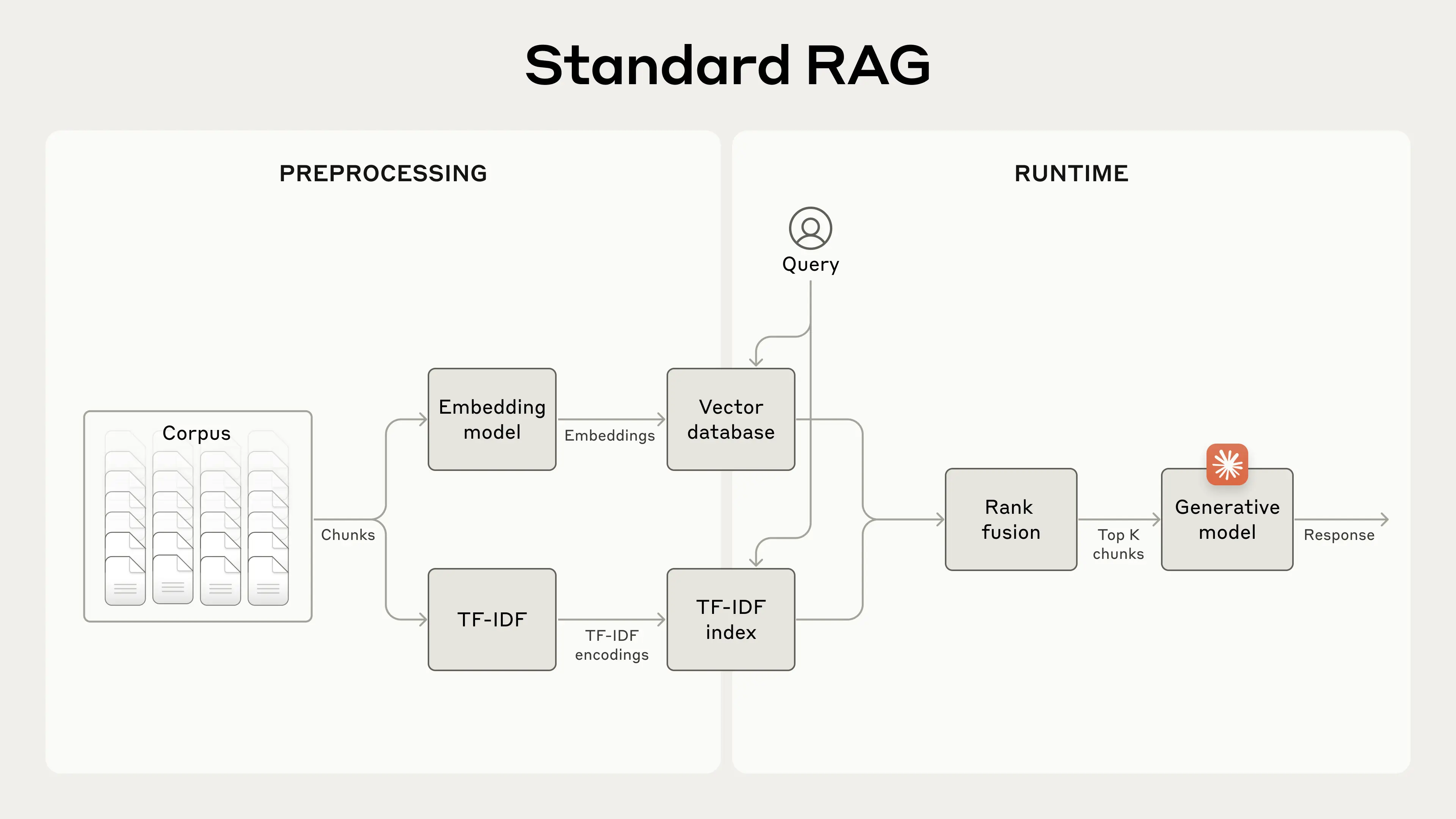
Traditional Chunking Methods
Traditional chunking methods aim to divide text into smaller segments for processing but often fall short in preserving the semantic integrity of the information. The two primary approaches in this category are character-based chunking and recursive chunking :
- Character-Based Chunking: This approach splits text into fixed-length segments, typically measured by the number of characters or tokens. While it ensures predictable and uniform chunk sizes, it often disrupts sentences or ideas mid-way, leading to incomplete or nonsensical chunks. For example, a sentence might be split across two chunks, losing coherence and context.
- Recursive Chunking: Recursive chunking uses natural separators like paragraphs, headings, or punctuation to create chunks. This approach produces more natural divisions compared to character-based methods. However, it doesn’t guarantee that each chunk is semantically coherent, as it relies purely on structural cues rather than the meaning of the content.
While these methods are straightforward to implement, they often result in fragmented or contextually incomplete segments, making them suboptimal for advanced workflows like Retrieval-Augmented Generation.
Semantic Chunking: A Smarter Approach to Text Segmentation
Semantic chunking is a cutting-edge technique designed to segment text into meaningful, conceptually distinct groups. Unlike traditional methods, which often rely on arbitrary separators or fixed lengths, semantic chunking ensures that each chunk represents a coherent idea, making it an essential tool for workflows like Retrieval-Augmented Generation (RAG) and beyond.
How Semantic Chunking Works
The process begins by breaking text into small initial chunks, often using recursive chunking methods as a foundation. These chunks are then embedded into high-dimensional vectors using transformer-based models, such as OpenAI’s text-embeddings-3-small or SentenceTransformers. The embeddings encode the semantic meaning of each chunk, enabling precise comparisons.
The next step involves calculating the cosine distances between embeddings of sequential chunks. Breakpoints are identified where the distances exceed a certain threshold, signaling significant semantic shifts. This approach ensures that the resulting chunks are both coherent within themselves and distinct from one another.
Refinements: Semantic Double Chunk Merging
To enhance this process further, an extension known as semantic double chunk merging has been introduced. This technique performs a second pass to re-evaluate and refine the chunking boundaries. For example, if chunks 1 and 3 are semantically similar but separated by chunk 2 (e.g., a mathematical formula or code block), they can be regrouped into a single coherent unit. This additional step improves the accuracy and utility of the chunking process. Applications and
Benefits
Semantic chunking proves invaluable in scenarios where understanding the underlying concepts of text is crucial:
- Retrieval-Augmented Generation (RAG): By creating semantically coherent chunks, RAG systems can retrieve and interpret relevant information more effectively.
- Text Summarization and Clustering: Large documents, such as books or research articles, can be grouped into clusters of related content, enabling faster insights.
- Visual Exploration: Dimensionality reduction techniques like UMAP, combined with clustering and labeling via LLMs, allow users to visualize the structure and flow of a document, providing both development insights and practical tools for analysis.
Challenges and Considerations
Despite its advantages, semantic chunking presents challenges. Determining optimal cosine distance thresholds and understanding what each chunk represents are highly application-dependent tasks. Fine-tuning these parameters requires careful consideration of the specific use case and the nature of the text.Semantic chunking is a powerful advancement in text processing, offering a meaningful way to dissect and interpret large volumes of information. Its ability to group related concepts and isolate distinct ideas makes it a valuable tool in both research and practical applications.
Contextual Retrieval: Enhancing Knowledge Access for AI Models
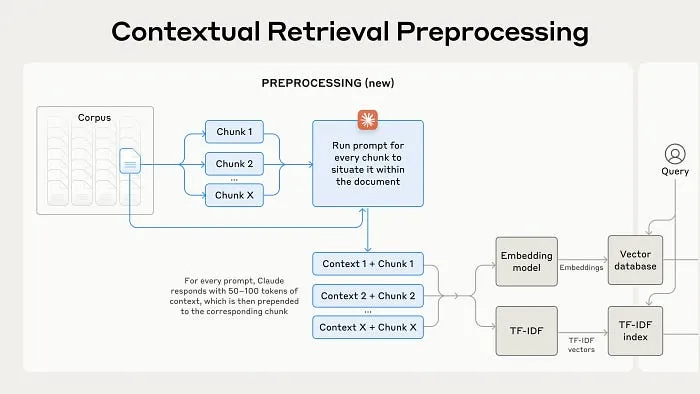
Contextual Retrieval is a technique designed to address this challenge by enhancing the context of each chunk before it is embedded and indexed. This method uses two key techniques: Contextual Embeddings and Contextual BM25 .
- Contextual Embeddings: Before creating embeddings for text chunks, explanatory context is added to each chunk. This context is specific to the chunk and situates it within the broader document, improving its relevance when retrieved. For example, a chunk stating "The company's revenue grew by 3%" might be augmented with the context "This chunk is from an SEC filing on ACME Corp's performance in Q2 2023."
- Contextual BM25: BM25 is a ranking function that uses lexical matching to find exact term matches. By applying BM25 in conjunction with semantic embeddings, Contextual Retrieval ensures that both exact matches and semantic similarities are used to retrieve the most relevant chunks, improving the overall retrieval accuracy.
This dual approach significantly reduces the number of failed retrievals, with improvements of up to 49% in accuracy. When combined with reranking, retrieval success can be enhanced by 67%. Implementing Contextual Retrieval To implement Contextual Retrieval, each chunk in a knowledge base is processed by adding context before embedding it. Claude, a powerful tool for this task, is used to automatically generate the contextual information. The process is simple and effective:
- Contextual Embeddings: Before creating embeddings for text chunks, explanatory context is added to each chunk. This context is specific to the chunk and situates it within the broader document, improving its relevance when retrieved. For example, a chunk stating "The company's revenue grew by 3%" might be augmented with the context "This chunk is from an SEC filing on ACME Corp's performance in Q2 2023."
- Contextual BM25: BM25 is a ranking function that uses lexical matching to find exact term matches. By applying BM25 in conjunction with semantic embeddings, Contextual Retrieval ensures that both exact matches and semantic similarities are used to retrieve the most relevant chunks, improving the overall retrieval accuracy.
Why Contextual Retrieval Works
Contextual Retrieval addresses a significant flaw in traditional RAG systems by ensuring that each chunk is rich in context. This method ensures that the AI model has a better understanding of the surrounding information, leading to more accurate and reliable responses.As knowledge bases grow larger, Contextual Retrieval becomes even more critical, allowing AI systems to scale while maintaining retrieval accuracy. By combining the power of semantic embeddings with lexical matching through BM25, Contextual Retrieval provides a comprehensive solution for improving the performance of AI models in specialized domains.
How SemDB Does It Better
SemDB goes beyond these traditional and emerging techniques by reimagining the chunking process from the ground up.
- Preprocessing for Context Clarity: Unlike standard systems, SemDB preprocesses the text before chunking or embedding. Pronouns are replaced with explicit references, long-range dependencies are resolved, and sentences are rewritten for clarity. This ensures that each sentence captures its full context independently, leading to more accurate embeddings.
- Recursive Chunking for Precision: Using recursive semantic chunking, SemDB can isolate highly specific sections without relying on comparisons between sentences. This approach enhances retrieval by ensuring that each chunk is both meaningful and distinct.
- Combining Multiple Strategies: SemDB doesn’t rely solely on contextual chunking. Its robust pipeline includes:
- Combining Multiple Strategies: SemDB doesn’t rely solely on contextual chunking. Its robust pipeline includes:
- Context Chunking: For preserving local context.
- Recursive Chunking: To create semantically coherent segments.
- Ontology-Based Enhancements: Leveraging domain-specific ontologies to enrich understanding and retrieval.
- Scalability for Large Documents: SemDB is adept at handling massive documents, such as 150+ page financial PDFs, by combining contextual embeddings with recursive chunking. This ensures that even granular details remain accessible while preserving overarching context.
Conclusion
Chunking is the unsung hero of Retrieval-Augmented Generation, enabling LLMs to process vast amounts of text effectively. While traditional and contextual chunking methods have improved retrieval accuracy, SemDB ’s innovative approach redefines the process. By combining advanced preprocessing, recursive chunking, and ontology-driven strategies, SemDB ensures unparalleled precision and scalability.The result? A system that doesn’t just retrieve information but truly understands it—delivering actionable insights, whether for analyzing financial documents, summarizing journal articles, or navigating complex knowledge bases.
Additional Resources
Introducing Contextual Retrieval
at
Anthropic
A Visual Exploration of Semantic Text Chunking
at
Toward Data Science by Robert Martin-Short