





Everything old is new again. A few years back, the world was on fire with key-value storage systems. I think it was Google's introduction of MapReduce that set the fire. It's funny because I remember reading in the '90s that the debate had been settled and that relational databases were provably the best way to store data in a manner that could easily be accessed.
But companies were founded and funded, and IPOs were launched. Somehow, here it is years later, and databases like SQL Server and Oracle still have their place. That's not to say that unstructured data is useless. It's wonderful.
For day-to-day operations, we use standard databases with standard database practices. That means foreign keys, basically third normal form, constraints, lots of type checking, etc. In fact, type checking is a cross-cutting pattern that we rely heavily upon to develop software quickly and bug-free. But that's a story for another post.
We have tools to quickly spin up schemas, modify them, materialize stored procedures, user interfaces, and all the good stuff. But no matter how well thought out and how flexible, some things don't belong in a row-column storage format. So we generally layer key-value storage on top of a relational database. Most information is well normalized, with database-level constraints, and queryable. But highly transitory data can live in unstructured storage. Years ago, that was XML. Nowadays, it's mostly JSON.
Data stored in JSON is "weakly typed" data. Data stored in a SQL column is "strongly typed". Each has it's own trade offs:
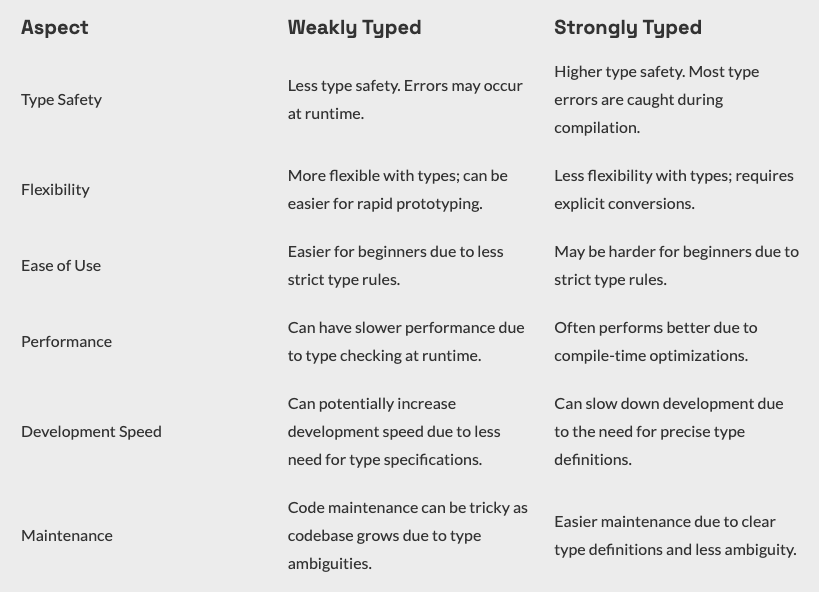
More importantly, we can easily write a SQL query on the strongly typed columns. It's less easy to query JSON. MSSQL 2016 added the ability to parse JSON on the fly with functions like JSON_VALUE and JSON_QUERY:

Our toolset gives us the ability to quickly add unstructured properties and, for the most part, treat them like structured and strongly-typed data. Our ORM layer can generate strongly-typed properties that back to unstructured JSON. User interfaces can bind to and update unstructured fields just like strongly-typed ones.
In the middle tier, this encapsulation makes the difference between strongly typed columns and weakly typed JSON transparent:
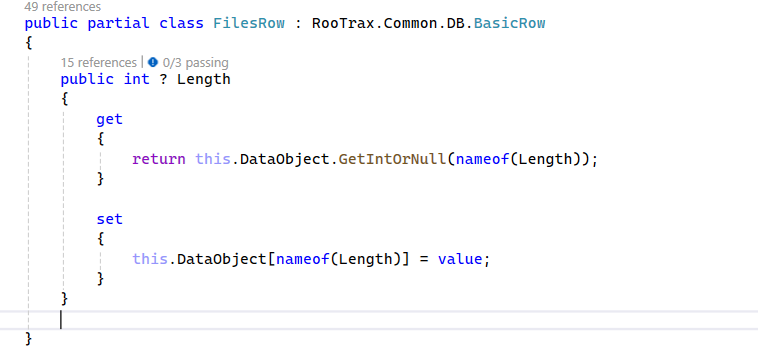
The DataObject property wraps a JSON property. All parsing, type conversion, validation, and serialization gets hidden. We expose a strongly typed property Length to the rest of the code:

But one thing has always been difficult with unstructured data:
querying
.
When we want to query, we have two options:
- Filter the data in the middle tier. This approach is slow computationally, but quick to program because it allows us to take advantage of the ORM's mappings.
- Filter the data in SQL (with SQL 2016 or above), and return the data to the middle tier already filtered. This approach is fast computationally, and slow programmatically.
Historically, the trade-off with unstructured data is that to query it, you need to parse it into a structured format, then run logic on that structured format, then serialize your results. It makes things like running standard SQL queries impossible. Well, not impossible, there's the JSON parsing built into SQL Server. But it's an afterthought.
We recently rolled out an upgrade to our stack: a mechanism to query unstructured data and structured data together in a family SQL syntax. Behind the scenes, a complex set of logic pulls the query apart, separates the structured and unstructured components of the query, and then executes those pieces intelligently in one of six optimized layers.
The six layers:
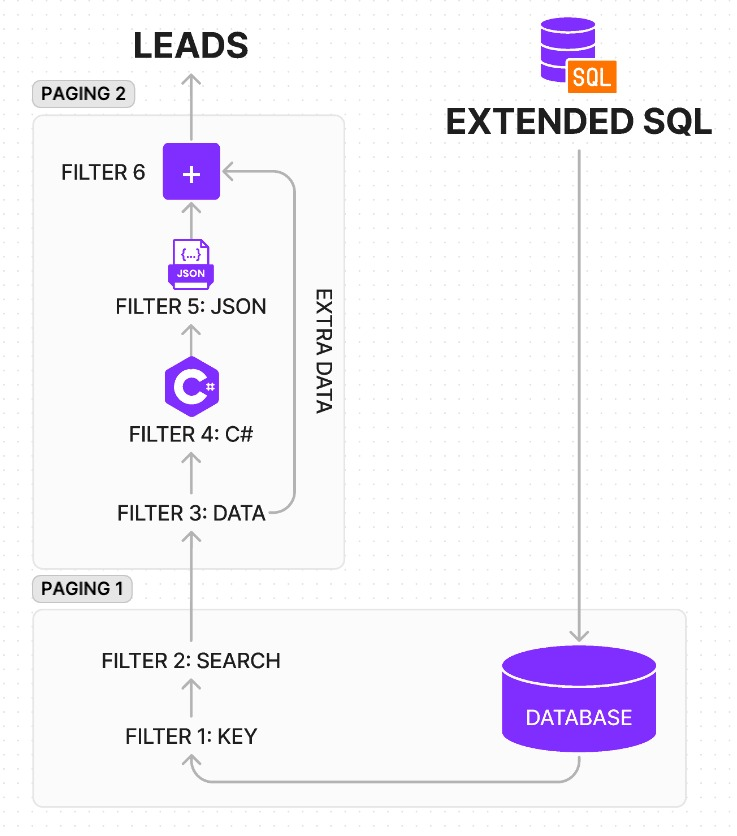
- Can the query utilize, in parts, an existing stored procedure?
- Can an existing stored procedure be wrapped with sorting and paging logic, materialized, and be used for part of the query?
- Can part of the query be paged, searched, or sorted in the database itself?
- Can strongly-typed columns be used to reduce the query load?
- Can the data be filtered as it is serialized into the ORM layer?
- Can caching already inside the ORM layer be used to fulfill part of the request?
Once all of these pieces are answered, the query is compiled into a series of SQL queries and intermediate language constructs to be run in the various layers. The compilation process is done one time so that the performance penalty is not paid with every lookup. Performing this sort of operation is not something to be done with each query. Only when we want to quickly roll out an update that involves complex querying or sorting with minimal database and code impacts. For highly utilized paths, we're still going to want to develop a hot path that uses even better constructs. For example, materializing an unstructured object and turning it into a structured table, a task we do quite often and have tools to manage.
Let's look at an example:
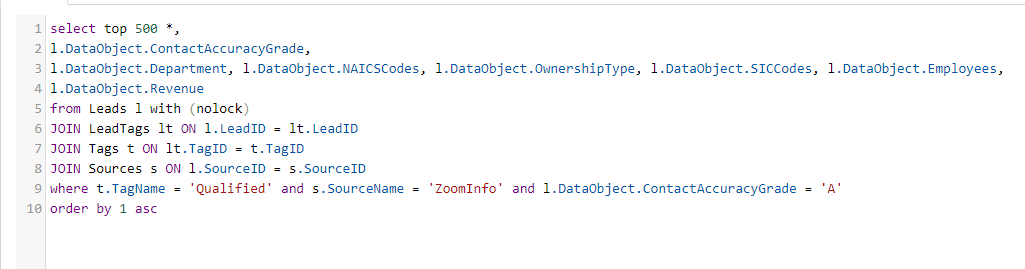
This is a query we might use to pull some leads from a lead system. Each "Lead" has a Data field containing structured JSON.
Leads can come from the web, cold calls, or various lead sources -- each with their own special fields. In this example, these leads are from a software called ZoomInfo that provides contact information, along with various additional fields to rate the quality of the leads.
The unstructured / structured query has two interesting pieces:
- The Column List
- The Where Clause
The Column List

This piece is asking the interpreter to parse the Data field and return each of these individual fields as columns.
Now we can operate on those fields just like normal fields. In this case we are exporting to a spreadsheet where JSON is not a nearly as sexy as rows and columns.
The Where Clause

The Where Clause is interesting because it requires the interpreter to separate this into two pieces: the SQL filter and the JSON filter. It's going to filter the rows with SQL first (without the JSON filter). Then it will filter those rows further with the JSON constraint.

It's important to do things in this exact order. The reverse order, filtering by JSON first then the JOINED columns, would cause unnecessary JSON parsing. JSON parsing is slow.
There is a little more complexity to this:

The TOP 500 clause tells SQL to return 500 rows. The interpreter and SQL work together to find enough rows from the first pass and second pass filters to fulfill this 500. We can't simply get 500 rows from SQL because they may not have the JSON requirements. On the other hand, we don't want to inspect every row in SQL as this table may (and does) contain a great number of rows.
We may want to chain other conditions, such as limiting the leads to those that are "A" and also have a greater than 92 score:
The interpreter will automatically cast the JSON data from string to a numerical type, then run the conversion operator. Ability to operate on non-string data types helps simply a lot of operations.
Conclusions
There is a ton more to this stack that I hope to share in future posts.
- Our developers use this tool to create reports, pull data dumps, or as a piece of a larger workflow.
- The SQL and UI stacks both share a similar components that allows the UI to utilize the same power without writing SQL.
- It's used extensively in our lead management system FeedFrenzy.AI
- We try to avoid one of implemetnations and give our reps the tools to be more effective. This feature underpins their ability to quickly sort through millions of leads and find those they truly care about.
- It's used in our AI based Patient Qualification system. The insurance billing team can quickly drill down into very granular qualifications.